来源:自学PHP网 时间:2021-03-25 10:51 作者:小飞侠 阅读:次
[导读] Linux安装Pytorch1.8GPU(CUDA11.1)的实现...
|
今天带来Linux安装Pytorch1.8GPU(CUDA11.1)的实现教程详解
先说下自己之前的环境(都是Linux系统,差别不大):
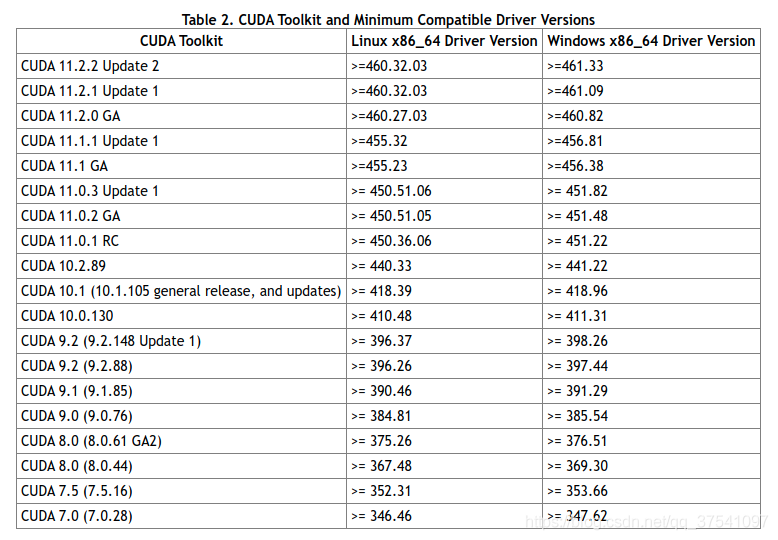
提示,如果想要保留之前的PyTorch1.6或1.7的环境,请不要卸载CUDA环境,可以通过Anaconda管理不同的环境,互不影响。但是需要注意你的NVIDIA驱动版本是否匹配。 在这里能够看到官方给的对应CUDA版本所需使用驱动版本。
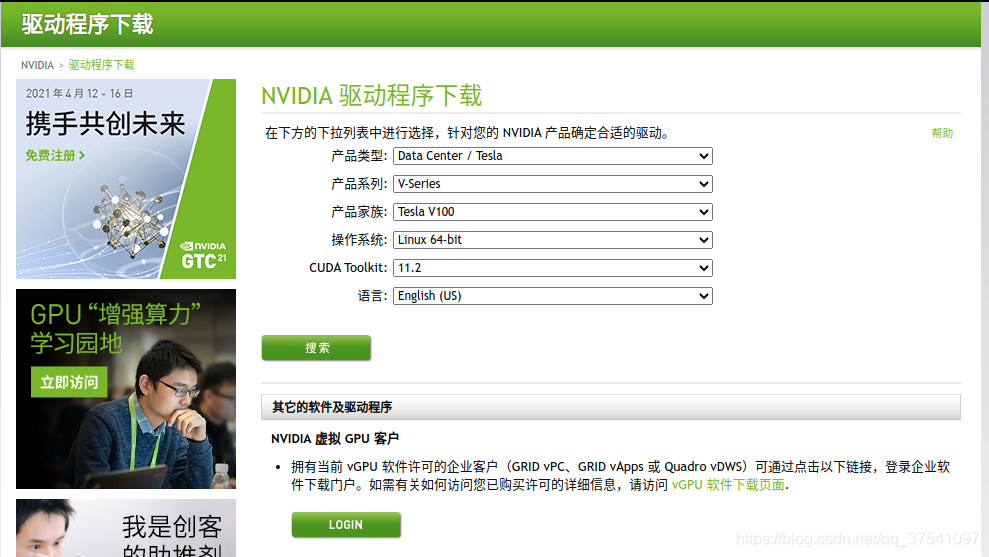
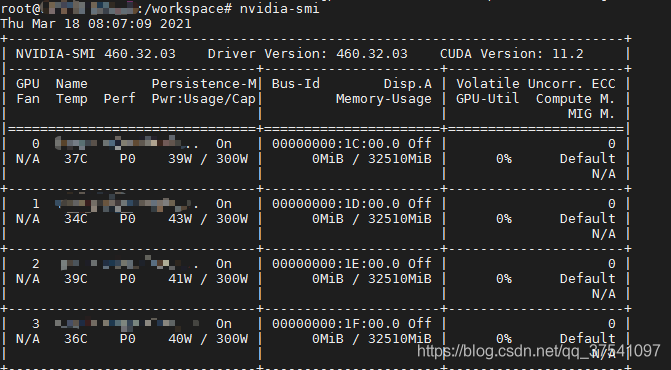
通过上表可以发现,如果要使用CUDA11.1,那么需要将显卡的驱动更新至455.23或以上(Linux x86_64环境)。由于我之前的驱动版本是440.33.01,那么肯定不满足,所以需要更新下显卡的驱动。通过以下指令可以查看你电脑上的驱动版本: nvidia-smi 如果你的驱动版本是满足的,那么可以直接跳到创建Pytorch1.8虚拟环境章节。 更新驱动卸载旧驱动我之前安装的是NVIDIA-440的版本,找到之前下载的安装程序,然后打开终端通过以下指令进行卸载: sh ./NVIDIA-Linux-x86_64-440.33.01.run --uninstall 安装新驱动 1)下载驱动,直接去NVIDIA官网下载:https://www.nvidia.cn/Download/index.aspx?lang=cn
根据你的GPU型号以及操作信息选择对应的驱动,注意CUDA Toolkit11版的当前可选的只有11.0和11.2,而我们要装的是11.1所以选择11.2即可。 2)关闭Xserver服务 (如果没有安装桌面系统可以跳过) systemctl status gdm.service 显示结果:
关闭gdm服务: systemctl stop gdm.service 注意,如果还开启了类似VNC远程桌面的服务也要记得关闭。 3)安装新版本驱动 sh ./NVIDIA-Linux-x86_64-460.32.03.run 4)检查nvidia服务 nvidia-smi 5)再次开启桌面服务、VNC等 systemctl start gdm.service 创建PyTorch1.8虚拟环境为了不同版本之间的环境互相隔离,强烈建议使用Anaconda的虚拟环境。其实使用起来也非常简单: 创建虚拟环境,这里我创建了一个名为torch18的虚拟环境,并且创建python3.8的编译环境。 conda create -n torch18 python=3.8 安装完成后,激活虚拟环境 conda activate torch18 接着安装点常用的包,这里直接通过 pip install -r requirements.txt
numpy==1.17.0 matplotlib==3.2.1 lxml==4.6.2 tqdm==4.42.1 如果需要退出虚拟环境,执行以下指令即可: conda deactivate 安装PyTorch1.8在线安装进入PyTorch官网:https://pytorch.org/
我们通过选择自己的系统类型、安装方式以及CUDA的版本可以得到对应的安装指令。官方默认会顺带安装torchvision和torchaudio但我只需要torchvision所以通过以下指令安装 (注意,要进入对应的虚拟环境安装,例如上面的torch18环境): pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html 安装完成后就可以使用了,不需要在单独安装CUDA,并且不会影响之前安装的CUDA版本。 下面进行简单的测试: 首先在终端输入 pyhton 然后导入 import torch torch.cuda.is_available() 如果打印的是
离线安装有些时候,可能你的设备无法连接外网,此时需要提前准备好需要安装的whl文件,那么我们这里就以
我们在这里可以找到我们需要的 进入对应虚拟环境 conda activate torch18 安装torch pip install torch-1.8.0+cu111-cp38-cp38-linux_x86_64.whl 安装torchvison pip install torchvision-0.9.0+cu111-cp38-cp38-linux_x86_64.whl 安装完成后进行简单的测试: 首先在终端输入 pyhton 然后导入 import torch torch.cuda.is_available() 如果打印的是
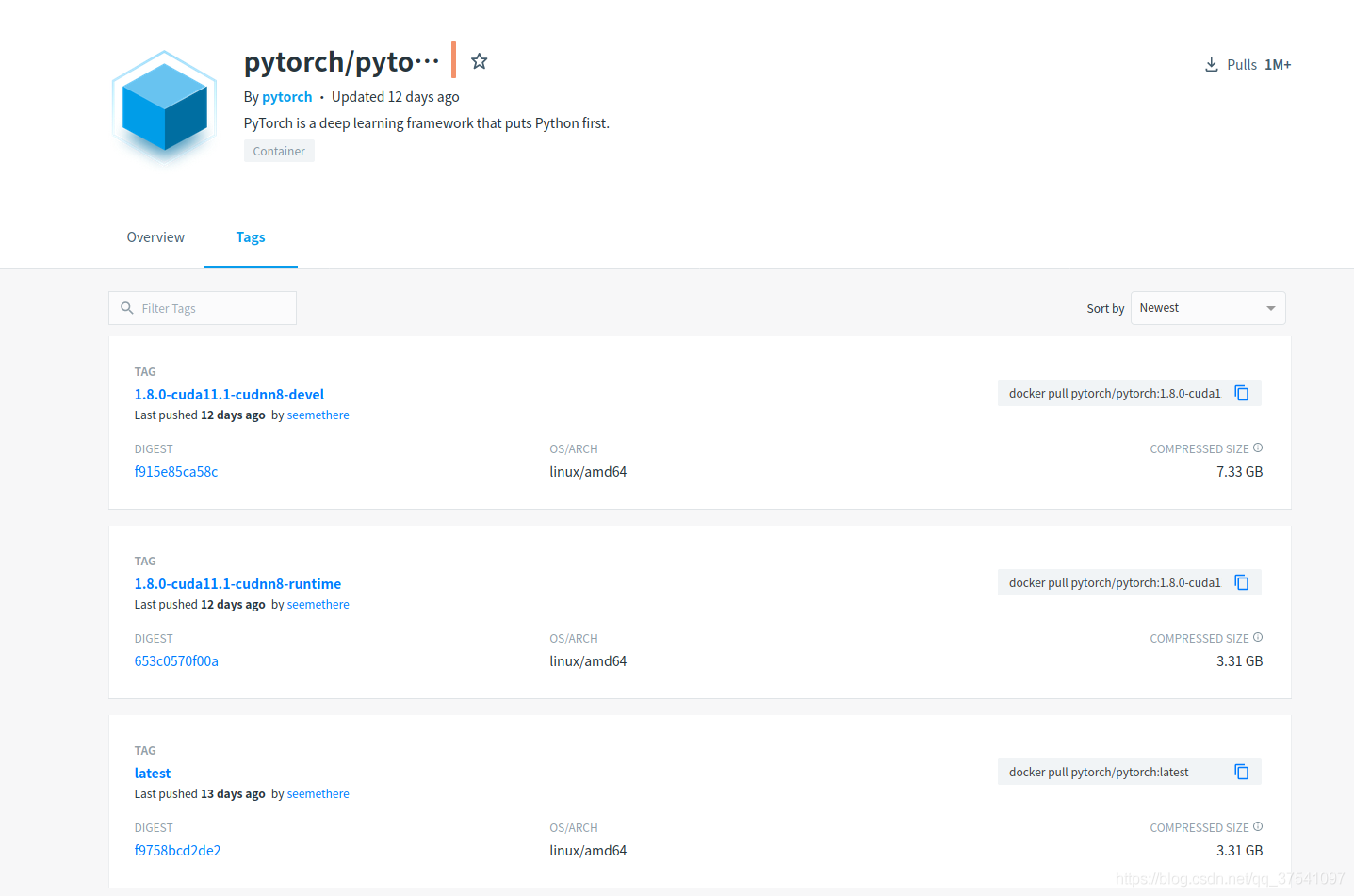
通过docker安装在有些情况下是需要使用docker来跑深度学习环境的(现在很多大公司都是使用paas平台来部署的)。那么我们就需要使用pytorch官方的docker镜像了。我们可以在docker hub上去搜索相关镜像,https://registry.hub.docker.com/。下图是我搜索的pytorch字段的结果(点击Tags后)。
我们可以看到当前最新的docker 镜像有 1)我们直接通过以下指令就能pull这个镜像了 docker pull pytorch/pytorch:1.8.0-cuda11.1-cudnn8-runtime 2)注意,在启动镜像前需要确保已安装 distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo 安装 首先根据你的系统类型以及版本下载对应 distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo 清空yum的过期缓存数据(如果不是root用户需要加sudo) yum clean expire-cache 安装 yum install -y nvidia-docker2 重启docker服务(如果不是root用户需要加sudo) systemctl restart docker 3)通过docker启动pytorch1.8.0容器 docker run --gpus all --rm -it --ipc=host pytorch/pytorch:1.8.0-cuda11.1-cudnn8-runtime 4)进入容器后可以通过
5)接着进入python环境简单测试下pytorch能否正常调用GPU(打印True为成功) import torch torch.cuda.is_available()
到此这篇关于Linux安装Pytorch1.8GPU(CUDA11.1)的实现的文章就介绍到这了,更多相关Linux安装Pytorch GPU 内容请搜索自学php网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学php网! 以上就是关于Linux安装Pytorch1.8GPU(CUDA11.1)的实现全部内容,感谢大家支持自学php网。 |
自学PHP网专注网站建设学习,PHP程序学习,平面设计学习,以及操作系统学习
京ICP备14009008号-1@版权所有www.zixuephp.com
网站声明:本站所有视频,教程都由网友上传,站长收集和分享给大家学习使用,如由牵扯版权问题请联系站长邮箱904561283@qq.com