来源:自学PHP网 时间:2015-04-14 12:58 作者: 阅读:次
[导读] 内容概要本篇文章主要讲解如何在微信公众帐号上实现历史上的今天功能。这个例子本身并不复杂,但希望通过对它的学习,读者能够对正则表达式有一个新的认识,能够学会运用现有...
|
内容概要 本篇文章主要讲解如何在微信公众帐号上实现“历史上的今天”功能。这个例子本身并不复杂,但希望通过对它的学习,读者能够对正则表达式有一个新的认识,能够学会运用现有的网络资源丰富自己的公众账号。
何谓历史上的今天 回顾历史的长河,历史是生活的一面镜子;以史为鉴,可以知兴衰;历史上的每一天,都是喜忧参半;可以了解历史的这一天发生的事件,借古可以鉴今,历史是不能忘记的。查看历史上每天发生的重大事情,增长知识,开拓眼界,提高人文素养。
寻找接口(数据源) 要实现查询“历史上的今天”,首先我们要找到相关数据源。笔者经过搜索发现,网络上几乎没有现成的“历史上的今天”API可以使用,所以我们只能通过爬取、解析网页源代码的方式得到我们需要的数据。笔者发现网站http://www.rijiben.com/上包含“历史上的今天”功能,就用它做数据源了。
开发步骤 为了便于读者理解,我们需要清楚该应用实例的开发步骤,主要如下: 1)发起HTTP GET请求,获取网页源代码。 2)运用正则表达式从网页源代码中抽取我们需要的数据。 3)对抽取得到的数据进行加工(使内容呈现更加美观)。 4)将以上三步进行封装,供外部调用。 5)在公众账号后台调用封装好的“历史上的今天”查询方法。
代码实现 笔者将上述步骤1)、2)、3)中的代码实现封装成了TodayInHistoryService类,并对外提供了getTodayInHistory()方法来获取“历史上的今天”。实现代码如下:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 历史上的今天查询服务
*
* @author liufeng
* @date 2013-10-16
*
*/
public class TodayInHistoryService {
/**
* 发起http get请求获取网页源代码
*
* @param requestUrl
* @return
*/
private static String httpRequest(String requestUrl) {
StringBuffer buffer = null;
try {
// 建立连接
URL url = new URL(requestUrl);
HttpURLConnection httpUrlConn = (HttpURLConnection) url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET");
// 获取输入流
InputStream inputStream = httpUrlConn.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(inputStream, "utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
// 读取返回结果
buffer = new StringBuffer();
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
// 释放资源
bufferedReader.close();
inputStreamReader.close();
inputStream.close();
httpUrlConn.disconnect();
} catch (Exception e) {
e.printStackTrace();
}
return buffer.toString();
}
/**
* 从html中抽取出历史上的今天信息
*
* @param html
* @return
*/
private static String extract(String html) {
StringBuffer buffer = null;
// 日期标签:区分是昨天还是今天
String dateTag = getMonthDay(0);
Pattern p = Pattern.compile("(.*)(<div class=\"listren\">)(.*?)(</div>)(.*)");
Matcher m = p.matcher(html);
if (m.matches()) {
buffer = new StringBuffer();
if (m.group(3).contains(getMonthDay(-1)))
dateTag = getMonthDay(-1);
// 拼装标题
buffer.append("≡≡ ").append("历史上的").append(dateTag).append(" ≡≡").append("\n\n");
// 抽取需要的数据
for (String info : m.group(3).split(" ")) {
info = info.replace(dateTag, "").replace("(图)", "").replaceAll("</?[^>]+>", "").trim();
// 在每行末尾追加2个换行符
if (!"".equals(info)) {
buffer.append(info).append("\n\n");
}
}
}
// 将buffer最后两个换行符移除并返回
return (null == buffer) ? null : buffer.substring(0, buffer.lastIndexOf("\n\n"));
}
/**
* 获取前/后n天日期(M月d日)
*
* @return
*/
private static String getMonthDay(int diff) {
DateFormat df = new SimpleDateFormat("M月d日");
Calendar c = Calendar.getInstance();
c.add(Calendar.DAY_OF_YEAR, diff);
return df.format(c.getTime());
}
/**
* 封装历史上的今天查询方法,供外部调用
*
* @return
*/
public static String getTodayInHistoryInfo() {
// 获取网页源代码
String html = httpRequest("http://www.rijiben.com/");
// 从网页中抽取信息
String result = extract(html);
return result;
}
/**
* 通过main在本地测试
*
* @param args
*/
public static void main(String[] args) {
String info = getTodayInHistoryInfo();
System.out.println(info);
}
}
代码解读:
1)27-58行代码是httpRequest()方法,用于发起http get请求,获取指定url的网页源代码。 2)66-92行代码是extract()方法,运用正则表达式从网页源代码中抽取“历史上的今天”数据。 3)111-118行代码是getTodayInHistory()方法,封装给外部调用查询“历史上的今天”。 4)125-128行代码是main方法,用于在本地的开发工具中测试。 5)75-76行代码的作用是判断获取到的“历史上的今天”数据是当天的还是前一天的(因为不能保证www.rijiben.com上的数据一定在凌晨零点准时更新,所以为了保证数据的准确性必须做此判断)。 6)第71行代码是本文的重点,笔者编写的正则表达式规则是“(.*)(<div class=\"listren\">)(.*?)(</div>)(.*)”。正则表达式规则需要根据网页源代码进行编写的,特别是包含“历史上的今天”数据的那部分HTML标签,所以我们先来查看网页源代码。通过httpRequest("http://www.rijiben.com/")方法获取到的网页源代码,与我们通过浏览器访问http://www.rijiben.com/页面再点击右键选择“查看网页源代码”所得到的结果完全一致。我们通过浏览器查看http://www.rijiben.com/的网页源代码,然后找到“历史上的今天”数据所在位置,如下图所示:
从上面的源代码截图中可以看到,我们需要的数据被包含在<div class="listren">标签内,这样就不难理解为什么正则表达式要这样写: (.*)(<div class=\"listren\">)(.*?)(</div>)(.*) 我们使用括号()将正则表达式规则分成了5组,下面是这些分组的说明: 第1组:(.*)表示网页源代码中<div class="listren">标签之前还有任意多个字符。 掌握了正则表达式规则的含义,就不难理解为什么在extract()方法中全都是在使用m.group(3),因为m.group(3)就表示匹配到数据的第3个分组。m.group(3)的内容如下:
<ul> <li><a href="/news6836/" title="0690年10月16日 武则天登上皇位">0690年10月16日 武则天登上皇位</a> (图)</li> <li><a href="/news6837/" title="1854年10月16日 唯美主义运动的倡导者王尔德诞辰">1854年10月16日 唯美主义运动的倡导者王尔德诞辰</a> </li> <li><a href="/news6838/" title="1854年10月16日 德国社会主义活动家考茨基诞生">1854年10月16日 德国社会主义活动家考茨基诞生</a> </li> <li><a href="/news6839/" title="1908年10月16日 阿尔巴尼亚领导人恩维尔·霍查诞辰">1908年10月16日 阿尔巴尼亚领导人恩维尔·霍查诞辰</a> (图)</li> <li><a href="/news6840/" title="1913年10月16日 中国“两弹一星”元勋钱三强诞辰">1913年10月16日 中国“两弹一星”元勋钱三强诞辰</a> (图)</li> <li><a href="/news6841/" title="1922年10月16日 开滦煤矿工人罢工失败">1922年10月16日 开滦煤矿工人罢工失败</a> (图)</li> <li><a href="/news6842/" title="1927年10月16日 德国诺贝尔文学奖得主格拉斯诞生">1927年10月16日 德国诺贝尔文学奖得主格拉斯诞生</a> (图)</li> <li><a href="/news6843/" title="1933年10月16日 抗日同盟军失败">1933年10月16日 抗日同盟军失败</a> (图)</li> <li><a href="/news6844/" title="1950年10月16日 人民解放军进军西藏">1950年10月16日 人民解放军进军西藏</a> (图)</li> <li><a href="/news6845/" title="1954年10月16日 俞平伯《关于红楼梦研究问题的信》发表">1954年10月16日 俞平伯《关于红楼梦研究问题的信》发表</a> (图)</li> <li><a href="/news6846/" title="1959年10月16日 美军将领、国务卿马歇尔去世">1959年10月16日 美军将领、国务卿马歇尔去世</a> (图)</li> <li><a href="/news6847/" title="1964年10月16日 勃列日涅夫取代赫鲁晓夫 成为苏共中央第一书记">1964年10月16日 勃列日涅夫取代赫鲁晓夫 成为苏共中央第一书记</a> </li> <li><a href="/news6848/" title="1964年10月16日 我国第一颗原子弹爆炸成功">1964年10月16日 我国第一颗原子弹爆炸成功</a> (图)</li> <li><a href="/news6849/" title="1973年10月16日 震撼世界的石油危机爆发">1973年10月16日 震撼世界的石油危机爆发</a> (图)</li> <li><a href="/news6850/" title="1978年10月16日 约翰·保罗二世当选新教皇">1978年10月16日 约翰·保罗二世当选新教皇</a> </li> <li><a href="/news6851/" title="1979年10月16日 哈克将军宣布巴基斯坦推迟大选解散政党">1979年10月16日 哈克将军宣布巴基斯坦推迟大选解散政党</a> </li> <li><a href="/news6852/" title="1984年10月16日 图图主教荣获“诺贝尔和平奖”">1984年10月16日 图图主教荣获“诺贝尔和平奖”</a> </li> <li><a href="/news6853/" title="1988年10月16日 北京正负电子对撞机对撞成功">1988年10月16日 北京正负电子对撞机对撞成功</a> (图)</li> <li><a href="/news6854/" title="1991年10月16日 美国小镇枪杀案22人丧生">1991年10月16日 美国小镇枪杀案22人丧生</a> </li> <li><a href="/news6855/" title="1991年10月16日 莫扎特死因有新说">1991年10月16日 莫扎特死因有新说</a> </li> <li><a href="/news6856/" title="1991年10月16日 钱学森获“国家杰出贡献科学家”殊荣">1991年10月16日 钱学森获“国家杰出贡献科学家”殊荣</a> (图)</li> <li><a href="/news6857/" title="1994年10月16日 德国总理科尔四连任">1994年10月16日 德国总理科尔四连任</a> </li> <li><a href="/news6858/" title="1994年10月16日 第十二届广岛亚运会闭幕">1994年10月16日 第十二届广岛亚运会闭幕</a> </li> <li><a href="/news6859/" title="1994年10月16日 修秦陵制秦俑工匠墓葬被发现">1994年10月16日 修秦陵制秦俑工匠墓葬被发现</a> </li> <li><a href="/news6860/" title="1995年10月16日 美国百万黑人男子大游行">1995年10月16日 美国百万黑人男子大游行</a> (图)</li> </ul>
可以看到,通过正则表达式抽取得到的m.group(3)中仍然有大量的html标签、空格、换行、无关字符等。我们要想办法把它们全部过滤掉,第83行代码的作用正是如此。
组装文本消息
// 组装文本消息(历史上的今天) TextMessage textMessage = new TextMessage(); textMessage.setToUserName(fromUserName); textMessage.setFromUserName(toUserName); textMessage.setCreateTime(new Date().getTime()); textMessage.setMsgType(WeixinUtil.RESP_MESSAGE_TYPE_TEXT); textMessage.setFuncFlag(0); textMessage.setContent(TodayInHistoryService.getTodayInHistoryInfo());
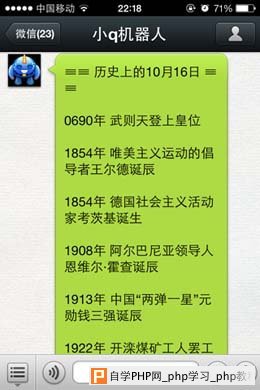
对于公众帐号的消息回复在本系列教程的第5篇已经讲的很详细了,所以在这里笔者只是简单的组装了文本消息。最后,我们来看一下在微信公众帐号上的演示效果:
说明:与其说这是一篇关于公众帐号应用开发的教程,倒不如说这是一篇关于网页数据爬取的教程。本文旨在为读者开辟思路,介绍一种数据获取方式。当然,这种做法也是有弊端的,当网页改版源代码结构发生变化时,就需要重新改写数据抽取代码。没有做不到,只有想不到! 如果觉得文章对你有所帮助,请通过留言或关注微信公众帐号xiaoqrobot来支持柳峰! |
自学PHP网专注网站建设学习,PHP程序学习,平面设计学习,以及操作系统学习
京ICP备14009008号-1@版权所有www.zixuephp.com
网站声明:本站所有视频,教程都由网友上传,站长收集和分享给大家学习使用,如由牵扯版权问题请联系站长邮箱904561283@qq.com