来源:自学PHP网 时间:2019-08-07 16:47 作者:小飞侠 阅读:次
[导读] Go routine调度详解...
|
goroutine简介 goroutine是go语言中最为NB的设计,也是其魅力所在,goroutine的本质是协程,是实现并行计算的核心。goroutine使用方式非常的简单,只需使用go关键字即可启动一个协程,并且它是处于异步方式运行,你不需要等它运行完成以后在执行以后的代码。 go func()//通过go关键字启动一个协程来运行函数 go routine的调度原理和操作系统的线层调度是比较相似的。这里我们将介绍go routine的相关知识。 goroutine(有人也称之为协程)本质上go的用户级线程的实现,这种用户级线程是运行在内核级线程之上。当我们在go程序中创建goroutine的时候,我们的这些routine将会被分配到不同的内核级线程中运行。一个内核级线程可能会负责多个routine的运行。而保证这些routine在内内核级线程安全、公平、高效运行的工作,就由调度器来实现。 goroutine内部原理 概念介绍 在进行实现原理之前,了解下一些关键性术语的概念。 并发 一个cpu上能同时执行多项任务,在很短时间内,cpu来回切换任务执行(在某段很短时间内执行程序a,然后又迅速得切换到程序b去执行),有时间上的重叠(宏观上是同时的,微观仍是顺序执行),这样看起来多个任务像是同时执行,这就是并发。 并行 当系统有多个CPU时,每个CPU同一时刻都运行任务,互不抢占自己所在的CPU资源,同时进行,称为并行。 进程 cpu在切换程序的时候,如果不保存上一个程序的状态(也就是我们常说的context--上下文),直接切换下一个程序,就会丢失上一个程序的一系列状态,于是引入了进程这个概念,用以划分好程序运行时所需要的资源。因此进程就是一个程序运行时候的所需要的基本资源单位(也可以说是程序运行的一个实体)。 线程 cpu切换多个进程的时候,会花费不少的时间,因为切换进程需要切换到内核态,而每次调度需要内核态都需要读取用户态的数据,进程一旦多起来,cpu调度会消耗一大堆资源,因此引入了线程的概念,线程本身几乎不占有资源,他们共享进程里的资源,内核调度起来不会那么像进程切换那么耗费资源。 协程 协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此,协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。线程和进程的操作是由程序触发系统接口,最后的执行者是系统;协程的操作执行者则是用户自身程序,goroutine也是协程。 Go调度的组成 Go的调度主要有四个结构组成,分别是:
Go程序的启动过程
创建goroutine:
创建内核级线程M 内核级线程由go的运行时根据实际情况创建,我们无法再go中创建内核级线程。那什么时候回创建内核级线程呢?当前程序等待运行的goroutine数量达到一定数量及存在空闲(为被分配给M)的P的时候,Go运行时就会创建一些M,然后将空闲的P分配给新建的内核级线程M,接着才是获取、运行goroutine。创建M的接口函数如下:
// 创建M的接口函数
void newm(void (*fn)(void), P *p)
// 分配P给M
if(m != &runtime・m0) {Â
acquirep(m->nextp);
m->nextp = nil;
}
// 获取goroutine并开始运行
schedule();
M的运行
static void schedule(void)
{
G *gp;
gp = runqget(m->p);
if(gp == nil)
gp = findrunnable();
// 如果P的类别不止一个goroutine,且调度器中有空闲的的P,就唤醒其他内核级线程M
if (m->p->runqhead != m->p->runqtail &&
runtime・atomicload(&runtime・sched.nmspinning) == 0 &&
runtime・atomicload(&runtime・sched.npidle) > 0) // TODO: fast atomic
wakep();
// 执行goroutine
execute(gp);
}
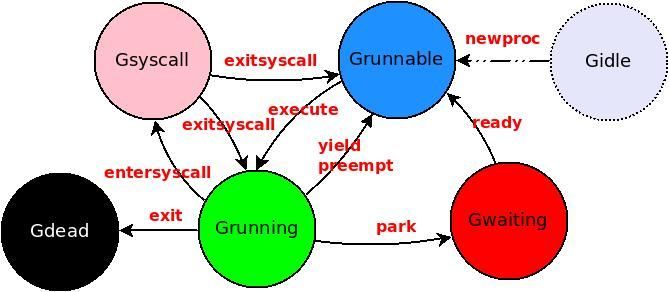
Routine状态迁移 前面说的是G,M是怎样创建的以及什么时候创建、运行。那么goroutine在M是是怎样进行调度的呢?这个才是goroutine的调度核心问题,即上面代码中的schedule。在说调度之前,我们必须知道goroutine的状态有什么,以及各个状态之间的关系。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学php网。 |
自学PHP网专注网站建设学习,PHP程序学习,平面设计学习,以及操作系统学习
京ICP备14009008号-1@版权所有www.zixuephp.com
网站声明:本站所有视频,教程都由网友上传,站长收集和分享给大家学习使用,如由牵扯版权问题请联系站长邮箱904561283@qq.com