来源:自学PHP网 时间:2015-04-16 10:50 作者: 阅读:次
[导读] 1,简介1 1mha简介MHA,即MasterHigh Availability Manager and Tools for MySQL,是日本的一位MySQL专家采用Perl语言编写的一个脚本管理工具,该工具仅适用于MySQLReplication(二层)环境,目的在于维...
|
1,简介1.1mha简介MHA,即MasterHigh Availability Manager and Tools for MySQL,是日本的一位MySQL专家采用Perl语言编写的一个脚本管理工具,该工具仅适用于MySQLReplication(二层)环境,目的在于维持Master主库的高可用性。
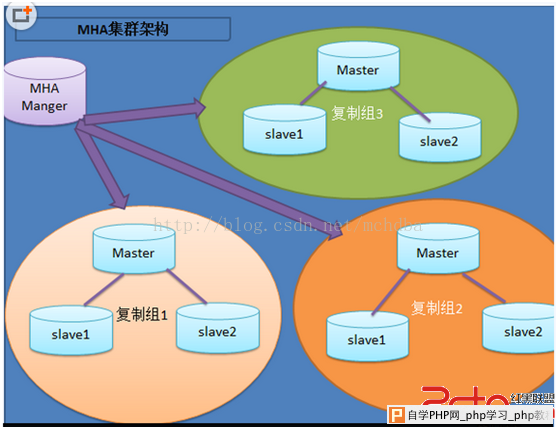
MHA(Master High Availability)是自动的master故障转移和Slave提升的软件包.它是基于标准的MySQL复制(异步/半同步). MHA有两部分组成:MHA Manager(管理节点)和MHA Node(数据节点). MHA Manager可以单独部署在一台独立机器上管理多个master-slave集群,也可以部署在一台slave上.MHA Manager探测集群的node节点,当发现master出现故障的时候,它可以自动将具有最新数据的slave提升为新的master,然后将所有其它的slave导向新的master上.整个故障转移过程对应用程序是透明的。 MHA node运行在每台MySQL服务器上(master/slave/manager),它通过监控具备解析和清理logs功能的脚本来加快故障转移的。
1.2,mha特点1. 10-30s实现master failover(9-12s可以检测到主机故障,7-10s可以关闭主机避免SB,在用很短的时间应用差异日志)
2. 部署简单,无需对现有M-S结构做任何改动(至少3台,保证切换后仍保持M-S结构)
3. 支持手动在线切换(主机硬件维护),downtime几乎很短0.5-2s
4. 保证故障切换后多从库数据的一致性
5. 完全自动化的failover及快速复制架构恢复方案(一主多从)
6. 恢复过程包括:选择新主库、确认从库间relaylog差异、新主库应用必要语句、其他从库同步差异语句、重新建立复制连接
2,工作原理
相较于其它HA软件,MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。 -从宕机崩溃的master保存二进制日志事件(binlogevents)。 -识别含有最新更新的slave。 -应用差异的中继日志(relay log)到其它slave。 -应用从master保存的二进制日志事件(binlogevents)。 -提升一个slave为新master。 -使其它的slave连接新的master进行复制。
3,mha工具包(1)、 Manager工具: - masterha_check_ssh : 检查MHA的SSH配置。 - masterha_check_repl : 检查MySQL复制。 - masterha_manager : 启动MHA。 - masterha_check_status : 检测当前MHA运行状态。 - masterha_master_monitor : 监测master是否宕机。 - masterha_master_switch : 控制故障转移(自动或手动)。 - masterha_conf_host : 添加或删除配置的server信息。
(2)、 Node工具(这些工具通常由MHAManager的脚本触发,无需人手操作)。 - save_binary_logs : 保存和复制master的二进制日志。 - apply_diff_relay_logs : 识别差异的中继日志事件并应用于其它slave。 - filter_mysqlbinlog : 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。 - purge_relay_logs : 清除中继日志(不会阻塞SQL线程)。
4,主机部署
5,生成ssh无密钥证书5.1 先在192.168.52.129上面生成密钥ssh-keygen -t dsa -P '' -f id_dsa Id_dsa.pub为公钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,过程如下:
cat id_dsa.pub >> authorized_keys
5.2 在192.168.52.130上面生产密钥ssh-keygen -t dsa -P '' -f id_dsa cat id_dsa.pub >> authorized_keys
5.3 在192.168.52.131上面生产密钥ssh-keygen -t dsa -P '' -f id_dsa cat id_dsa.pub >> authorized_keys
5.4 构造3个通用的authorized_keys在192.168.52.129上面操作: cd /root/.ssh #copy130和131上面的密钥过来 scp 192.168.52.130:/root/.ssh/id_dsa.pub./id_dsa.pub.130 scp 192.168.52.131:/root/.ssh/id_dsa.pub./id_dsa.pub.131 cat id_dsa.pub.130 >> authorized_keys cat id_dsa.pub.131 >> authorized_keys
查看生成的通用密钥 [root@data01 .ssh]# cat authorized_keys ssh-dssAAAAB3NzaC1kc3MAAACBAKe9oTz+hQ3vAUE+x7s2EIT6RSrlPoD2VHuSsDo+ZmAyv6+DD6/eVhVXrCyqzjQPJa6UI0PYjlPMk2r2wqdvC/YqQaLhFuQmsBQwrVA2xNHwhB3ic+Om44GVoiZFM7+bGAtfhQ9DLK2+sjfaa/oQfuDvTJ2SI/f0oG3wDGmokgdLAAAAFQC/O4R1yX1FxW7+dCKHhV+LQHWWHQAAAIADR5yqZGZCx8VB8Q6kAYg3cuUCCo3gF/hA5bHY+2xO5CcGAD1mq/l5v55QPUlGAH7btdmfip1tiaQ+V3N+Ektf2psM0uap/LKvbV2jQYKc2UZrpfF6R0lG+x9rpkxWMce1TJ4yANGOasjNjUV6Lg0RVDxLiMT4Ja4+edQVduYt2AAAAIBPNfJlyglZ5CwsI+v753tD8WT4GaH8ssNLpIKrH9qJU6OuT9MmniKE1RqZr+e5MCvkUAAXHFPq0DhHQlPKWqhIpVlu0E8Zsn9a5tv728JpIYz1umB5VLo2J5fhpobefD3AhjEHSyaubJgQG4Gu+jdwsR0H21xLNx0VoP8YPbYkAQ==root@data01 ssh-dssAAAAB3NzaC1kc3MAAACBAPtU+mTL9an88U1wfSwxdlHBg9n8eB9l218sXGLHwJyxNJN0pq4iPCLMfRxhM6T30HxUnyhghxBF2XvkAkMEjZ+IuCoA0mwRi1CcYSMh72SXqfRdgE2GpRBZDRRhlCIE5feNswWZdC7fIDmgNHtK5CFmJLcl+9Bkb3kfGqu8JOxbAAAAFQDo2YRMd5ZsfBRvPZcCYWcOsuy2oQAAAIEA4pGH2w7luN9JhJ0V6sDUUySg4R488yloKR/k4yD33qPXTejCiDUKUbanMLs6obQqxpbVvlhRT6cyo/le7PO6H8IzRHjFy65EPL0omn7J06PmHBUMqCn4jXo27EGXlRLavnonUf3tFeaVo7GxXerj71NdBKkQX7e/bgzD4d5v0PMAAACBAIhx1X50hlYzqPEZEDXTJmntLRXsMB20DvngvUcQLlgLozwfaNdJAQuYSGqklXYTquSmsyaTNJsxj8EkKG4XbM/7hHtNbV8KuAMJGT4Dm7jEdiKClyle2tIvVtonYaL41KeZVdn6Lk4lRYIFxpDoQHKXXr+XEFhLjoniT8urPISlroot@data02 ssh-dss AAAAB3NzaC1kc3MAAACBAJtC3j4Gq+zR7adyKFco/1hELblR65Af+Cgi81mfL+sJAFuOqPcFvDANhymBQ9ltH1N2/eDq1CrD0U9tRMxSwBvgiWZW9brkMpl5ix6oJSCBHdyqL6iuREk7CZ3V/y7P2V+TDCc+am5onMWDG1Af9o6CeA7CP92CHaUoltcXd7L7AAAAFQCqpeVqjbEs/lC/J1utfWrpGDxt8QAAAIB1aeB6C3S9t0dU3bEZs06DaooO46foBFMOI7u0w7uEWvj48UQF7W5Y++vjsiARxr6clk2g2T70n0fJmZCtMMiHqD6vyy8OOy8PzdUcQVAUW2GZQ8hn7M1U2GOz2KPo6uUbPiKkXilEfh9YRsyZyxMdmC4raPjPea8sj6favK8RbgAAAIAima6hWfBFsFcE1oh02xk7ydavHGJbHAlxeH9g9glE0FPmzPgWMFkYQnLsyV2z+ouMPFmERUPYzg1k/8Dhoxjp9j4JB6bIcPNtKdlS660NcFLxRtFAhrnzvLOTzXYzeIuZOlE0WcjeQGNpx8JHAef/3WzpHnVmnhbmlkBrZ8X/OQ==root@oraclem1 [root@data01 .ssh]#
看到authorized_keys文件里面有3行记录,分别代表了访问data01(192.168.52.129),oraclem1(192.168.52.131),data02(192.168.52.130)的公用密钥。然后把这个authorized_keys公钥文件copy到oraclem1(192.168.52.131)和data02(192.168.52.130)上面同一个目录下。Scp命令如下: scp authorized_keys192.168.52.130:/root/.ssh/ scp authorized_keys192.168.52.131:/root/.ssh/
5.5 开始check验证如下:[root@oraclem1 ~]# ssh 192.168.52.130 Last login: Tue Apr 7 02:40:40 2015 from data01 [root@data02 ~]# ssh 192.168.52.131 Last login: Tue Apr 7 02:40:56 2015 from 192.168.52.131 [root@oraclem1 ~]# ssh 192.168.52.130 Last login: Tue Apr 7 02:41:11 2015 from 192.168.52.131 [root@data02 ~]# ssh 192.168.52.129 Last login: Tue Apr 7 02:40:01 2015 from 192.168.52.131 [root@data01 ~]# ssh 192.168.52.131 Last login: Tue Apr 7 02:41:18 2015 from 192.168.52.130 [root@oraclem1 ~]# ssh 192.168.52.129 Last login: Tue Apr 7 02:41:26 2015 from data02 [root@data01 ~]# ssh 192.168.52.131 Last login: Tue Apr 7 02:41:31 2015 from 192.168.52.129 [root@oraclem1 ~]# ssh 192.168.52.130 Last login: Tue Apr 7 02:41:21 2015 from 192.168.52.131 [root@data02 ~]# ssh 192.168.52.129 Last login: Tue Apr 7 02:41:42 2015 from 192.168.52.131 [root@data01 ~] OK,3台服务器已经能实现两两互相ssh通了,不需要输入密码即可。 PS:如果不能实现任何两台主机互相之间可以无密码登录,后面的环节可能会有问题。
5.6 实现主机名hostname登录在3台服务器上,编辑/etc/hosts,追加入以下内容保存退出 192.168.52.129 data01 192.168.52.130 data02 192.168.52.131 oraclem1
验证主机名登录: [root@data02 ~]# ssh oraclem1 The authenticity of host 'oraclem1(192.168.52.131)' can't be established. RSA key fingerprint ise5:f0:ae:e3:14:35:2f:09:1f:88:dd:31:c3:1a:e1:73. Are you sure you want to continueconnecting (yes/no)? yes Warning: Permanently added 'oraclem1' (RSA)to the list of known hosts. Last login: Tue Apr 7 02:51:59 2015 from data01 [root@oraclem1 ~]# ssh data02 Last login: Tue Apr 7 02:52:10 2015 from data01 [root@data02 ~]# ssh oraclem1 Last login: Tue Apr 7 02:52:18 2015 from data02 [root@oraclem1 ~]# vim /etc/hosts [root@oraclem1 ~]# ssh data01 Last login: Tue Apr 7 02:52:06 2015 from data02 [root@data01 ~]# ssh data02 Last login: Tue Apr 7 02:52:21 2015 from oraclem1 [root@data02 ~]# ssh data01 Last login: Tue Apr 7 02:55:13 2015 from oraclem1 [root@data01 ~]# OK,看到可以实现通过主机名来无密码登录了。
6,准备好mysql主从环境
具体搭建过程,参考以前的blog:http://blog.csdn.net/mchdba/article/details/44734597 架构如下,一主二从的架构 Master主库à192.168.52.129,slave从库à192.168.52.130 Master 主库à192.168.52.129,slave从库à192.168.52.131
创建用户mha管理的账号,在所有mysql服务器上都需要执行: GRANT SUPER,RELOAD,REPLICATIONCLIENT,SELECT ON *.* TO manager@'192.168.52.%' IDENTIFIED BY 'manager_1234'; GRANT CREATE,INSERT,UPDATE,DELETE,DROP ON*.* TO manager@'192.168.52.%';
创建主从账号,在所有mysql服务器上都需要执行: GRANT RELOAD, SUPER, REPLICATION SLAVE ON*.* TO 'repl'@'192.168.52.%' IDENTIFIED BY 'repl_1234';
7,开始安装mhamha包括manager节点和data节点,data节点包括原有的MySQL复制结构中的主机,至少3台,即1主2从,当masterfailover后,还能保证主从结构;只需安装node包。manager server:运行监控脚本,负责monitoring 和 auto-failover;需要安装node包和manager包。
为了节省机器,可以从现有复制架构中选一台“闲置”从库作为manager server,比如:某台从库不对外提供读的服务,只是作为候选主库,或是专门用于备份。 7.1,在数据节点上安装mha首先安装yum -y install perl-DBD-MySQL tar -zxvpf mha4mysql-node-0.56.tar.gz perl Makefile.PL make && make install
7.2 在管理节点上安装mha首先安装perl的mysql包: yum install -y perl-DBD-MySQL yum install -y perl-Config-Tiny yum install -y perl-Log-Dispatch yum install -y perl-Parallel-ForkManager yum install -y perl-Config-IniFiles 一些安装失败,可以直接下载rpm包安装: wgetftp://ftp.muug.mb.ca/mirror/centos/5.10/os/x86_64/CentOS/perl-5.8.8-41.el5.x86_64.rpm wgetftp://ftp.muug.mb.ca/mirror/centos/6.5/os/x86_64/Packages/compat-db43-4.3.29-15.el6.x86_64.rpm wgethttp://downloads.naulinux.ru/pub/NauLinux/6x/i386/sites/School/RPMS/perl-Log-Dispatch-2.27-1.el6.noarch.rpm
wget http://dl.fedoraproject.org/pub/epel/6/i386/perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm
wget http://dl.fedoraproject.org/pub/epel/6/i386/perl-Mail-Sender-0.8.16-3.el6.noarch.rpm wget http://dl.fedoraproject.org/pub/epel/6/i386/perl-Mail-Sendmail-0.79-12.el6.noarch.rpm
wget http://mirror.centos.org/centos/6/os/x86_64/Packages/perl-Time-HiRes-1.9721-136.el6.x86_64.rpm
下载完后,一个个rpm安装好 如果最后还是安装不好,可以尝试一下perl CPAN的方式: perl -MCPAN -e shell cpan[1]> install Log::Dispatch
然后通过perlMakefile.PL检查mha的perl安装环境,如下所示: [root@oraclem1 mha4mysql-manager-0.56]#perl Makefile.PL *** Module::AutoInstall version 1.03 *** Checking for Perl dependencies... [Core Features] - DBI ...loaded. (1.609) - DBD::mysql ...loaded. (4.013) - Time::HiRes ...loaded. (1.9726) - Config::Tiny ...loaded. (2.12) - Log::Dispatch ...loaded. (2.44) - Parallel::ForkManager ...loaded. (0.7.9) - MHA::NodeConst ...loaded. (0.56) *** Module::AutoInstall configurationfinished. Generating a Unix-style Makefile Writing Makefile for mha4mysql::manager Writing MYMETA.yml and MYMETA.json [root@oraclem1 mha4mysql-manager-0.56]#
然后解压缩安装: tar -xvf mha4mysql-manager-0.56.tar.gz cd mha4mysql-manager-0.56 perl Makefile.PL make && make install
7.3 编辑管理节点配置
在管理节点192.168.52.129上面
[root@data01 mha4mysql-manager-0.56]# vim/etc/masterha/app1.cnf
[server default] manager_workdir=/var/log/masterha/app1 manager_log=/var/log/masterha/app1/manager.log
ssh_user=root #ssh免密钥登录的帐号名 repl_user=repl #mysql复制帐号,用来在主从机之间同步二进制日志等 repl_password=repl_1234 ping_interval=1 #ping间隔,用来检测master是否正常
[server1] hostname=192.168.52.129 candidate_master=1 #master机宕掉后,优先启用这台作为新master master_binlog_dir=/home/data/mysql/binlog/
[server2] hostname=192.168.52.130 #candidate_master=1 master_binlog_dir=/home/data/mysql/binlog/
[server3] hostname=192.168.52.131 #candidate_master=1 master_binlog_dir=/home/data/mysql/binlog/
#[server4] #hostname=host4 #no_master=1
7.4 利用mha工具检测ssh然后check ssh成功,采用命令:masterha_check_ssh --conf=/etc/masterha/app1.cnf,如下所示: [root@data01 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf Tue Apr 7 02:56:12 2015 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Apr 7 02:56:12 2015 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Tue Apr 7 02:56:12 2015 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Tue Apr 7 02:56:12 2015 - [info] Starting SSH connection tests.. Tue Apr 7 02:56:15 2015 - [debug] Tue Apr 7 02:56:12 2015 - [debug] Connecting via SSH from root@192.168.52.129(192.168.52.129:22) to root@192.168.52.130(192.168.52.130:22).. Warning: Permanently added '192.168.52.129' (RSA) to the list of known hosts. Tue Apr 7 02:56:13 2015 - [debug] ok. Tue Apr 7 02:56:13 2015 - [debug] Connecting via SSH from root@192.168.52.129(192.168.52.129:22) to root@192.168.52.131(192.168.52.131:22).. Tue Apr 7 02:56:15 2015 - [debug] ok. Tue Apr 7 02:56:15 2015 - [debug] Tue Apr 7 02:56:13 2015 - [debug] Connecting via SSH from root@192.168.52.130(192.168.52.130:22) to root@192.168.52.129(192.168.52.129:22).. Tue Apr 7 02:56:14 2015 - [debug] ok. Tue Apr 7 02:56:14 2015 - [debug] Connecting via SSH from root@192.168.52.130(192.168.52.130:22) to root@192.168.52.131(192.168.52.131:22).. Tue Apr 7 02:56:15 2015 - [debug] ok. Tue Apr 7 02:56:16 2015 - [debug] Tue Apr 7 02:56:13 2015 - [debug] Connecting via SSH from root@192.168.52.131(192.168.52.131:22) to root@192.168.52.129(192.168.52.129:22).. Tue Apr 7 02:56:15 2015 - [debug] ok. Tue Apr 7 02:56:15 2015 - [debug] Connecting via SSH from root@192.168.52.131(192.168.52.131:22) to root@192.168.52.130(192.168.52.130:22).. Tue Apr 7 02:56:16 2015 - [debug] ok. Tue Apr 7 02:56:16 2015 - [info] All SSH connection tests passed successfully. [root@data01 ~]#
7.5 使用mha工具check检查repl环境检测命令为:masterha_check_repl--conf=/etc/masterha/app1.cnf,检测结果如下: [root@oraclem1 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf Fri Apr 10 01:02:18 2015 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Apr 10 01:02:18 2015 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Fri Apr 10 01:02:18 2015 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Fri Apr 10 01:02:18 2015 - [info] MHA::MasterMonitor version 0.56. Fri Apr 10 01:02:18 2015 - [info] Multi-master configuration is detected. Current primary(writable) master is 192.168.52.129(192.168.52.129:3306) Fri Apr 10 01:02:18 2015 - [info] Master configurations are as below: Master 192.168.52.130(192.168.52.130:3306), replicating from 192.168.52.129(192.168.52.129:3306), read-only Master 192.168.52.129(192.168.52.129:3306), replicating from 192.168.52.130(192.168.52.130:3306) Fri Apr 10 01:02:18 2015 - [info] GTID failover mode = 0 Fri Apr 10 01:02:18 2015 - [info] Dead Servers: Fri Apr 10 01:02:18 2015 - [info] Alive Servers: Fri Apr 10 01:02:18 2015 - [info] 192.168.52.129(192.168.52.129:3306) Fri Apr 10 01:02:18 2015 - [info] 192.168.52.130(192.168.52.130:3306) Fri Apr 10 01:02:18 2015 - [info] 192.168.52.131(192.168.52.131:3306) Fri Apr 10 01:02:18 2015 - [info] Alive Slaves: Fri Apr 10 01:02:18 2015 - [info] 192.168.52.130(192.168.52.130:3306) Version=5.6.12-log (oldest major version between slaves) log-bin:enabled Fri Apr 10 01:02:18 2015 - [info] Replicating from 192.168.52.129(192.168.52.129:3306) Fri Apr 10 01:02:18 2015 - [info] 192.168.52.131(192.168.52.131:3306) Version=5.6.12-log (oldest major version between slaves) log-bin:enabled Fri Apr 10 01:02:18 2015 - [info] Replicating from 192.168.52.129(192.168.52.129:3306) Fri Apr 10 01:02:18 2015 - [info] Current Alive Master: 192.168.52.129(192.168.52.129:3306) Fri Apr 10 01:02:18 2015 - [info] Checking slave configurations.. Fri Apr 10 01:02:18 2015 - [info] Checking replication filtering settings.. Fri Apr 10 01:02:18 2015 - [info] binlog_do_db= user_db, binlog_ignore_db= information_schema,mysql,performance_schema,test Fri Apr 10 01:02:18 2015 - [info] Replication filtering check ok. Fri Apr 10 01:02:18 2015 - [info] GTID (with auto-pos) is not supported Fri Apr 10 01:02:18 2015 - [info] Starting SSH connection tests.. Fri Apr 10 01:02:20 2015 - [info] All SSH connection tests passed successfully. Fri Apr 10 01:02:20 2015 - [info] Checking MHA Node version.. Fri Apr 10 01:02:23 2015 - [info] Version check ok. Fri Apr 10 01:02:23 2015 - [info] Checking SSH publickey authentication settings on the current master.. Fri Apr 10 01:02:23 2015 - [info] HealthCheck: SSH to 192.168.52.129 is reachable. Fri Apr 10 01:02:23 2015 - [info] Master MHA Node version is 0.56. Fri Apr 10 01:02:23 2015 - [info] Checking recovery script configurations on 192.168.52.129(192.168.52.129:3306).. Fri Apr 10 01:02:23 2015 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/home/data/mysql/binlog/ --output_file=/var/tmp/save_binary_logs_test --manager_version=0.56 --start_file=mysql-bin.000183 Fri Apr 10 01:02:23 2015 - [info] Connecting to root@192.168.52.129(192.168.52.129:22).. Creating /var/tmp if not exists.. ok. Checking output directory is accessible or not.. ok. Binlog found at /home/data/mysql/binlog/, up to mysql-bin.000183 Fri Apr 10 01:02:23 2015 - [info] Binlog setting check done. Fri Apr 10 01:02:23 2015 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers.. Fri Apr 10 01:02:23 2015 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='manager' --slave_host=192.168.52.130 --slave_ip=192.168.52.130 --slave_port=3306 --workdir=/var/tmp --target_version=5.6.12-log --manager_version=0.56 --relay_dir=/home/data/mysql/data --current_relay_log=mysqld-relay-bin.000011 --slave_pass=xxx Fri Apr 10 01:02:23 2015 - [info] Connecting to root@192.168.52.130(192.168.52.130:22).. Checking slave recovery environment settings..
Relay log found at /home/data/mysql/data, up to mysqld-relay-bin.000013
Temporary relay log file is /home/data/mysql/data/mysqld-relay-bin.000013
Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Fri Apr 10 01:02:24 2015 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='manager' --slave_host=192.168.52.131 --slave_ip=192.168.52.131 --slave_port=3306 --workdir=/var/tmp --target_version=5.6.12-log --manager_version=0.56 --relay_log_info=/home/data/mysql/data/relay-log.info --relay_dir=/home/data/mysql/data/ --slave_pass=xxx Fri Apr 10 01:02:24 2015 - [info] Connecting to root@192.168.52.131(192.168.52.131:22).. Checking slave recovery environment settings..
Opening /home/data/mysql/data/relay-log.info ... ok.
Relay log found at /home/data/mysql/data, up to mysql-relay-bin.000023
Temporary relay log file is /home/data/mysql/data/mysql-relay-bin.000023
Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Fri Apr 10 01:02:26 2015 - [info] Slaves settings check done. Fri Apr 10 01:02:26 2015 - [info] 192.168.52.129(192.168.52.129:3306) (current master) +--192.168.52.130(192.168.52.130:3306) +--192.168.52.131(192.168.52.131:3306) Fri Apr 10 01:02:26 2015 - [info] Checking replication health on 192.168.52.130.. Fri Apr 10 01:02:26 2015 - [info] ok. Fri Apr 10 01:02:26 2015 - [info] Checking replication health on 192.168.52.131.. Fri Apr 10 01:02:26 2015 - [info] ok. Fri Apr 10 01:02:26 2015 - [warning] master_ip_failover_script is not defined. Fri Apr 10 01:02:26 2015 - [warning] shutdown_script is not defined. Fri Apr 10 01:02:26 2015 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK. [root@oraclem1 ~]#
8,管理mha操作8.1 启动managernohup masterha_manager --conf=/etc/masterha/app1.cnf < /dev/null >/logs/mha/app1/manager.log 2>&1 & 执行后台情形,如下所示:
[root@oraclem1 mha4mysql-manager-0.56]# nohup masterha_manager --conf=/etc/masterha/app1.cnf /logs/mha/app1/manager.log 2>&1 & [1] 8973 [root@oraclem1 mha4mysql-manager-0.56]# [root@oraclem1 mha4mysql-manager-0.56]# tail -f /logs/mha/app1/manager.log Fri Apr 10 02:46:43 2015 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Apr 10 02:46:43 2015 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Fri Apr 10 02:46:43 2015 - [info] Reading server configuration from /etc/masterha/app1.cnf..
8.2 使用masterha_check_status检测下[root@oraclem1 ~]# masterha_check_status--conf=/etc/masterha/app1.cnf app1 (pid:8973) is running(0:PING_OK),master:192.168.52.129 [root@oraclem1 ~]#
手动操作:
8.3 停止manager命令:masterha_stop --conf=/etc/masterha/app1.cnf [root@oraclem1 mha4mysql-manager-0.56]#masterha_stop --conf=/etc/masterha/app1.cnf Stopped app1 successfully. [1]+ Exit 1 nohupmasterha_manager --conf=/etc/masterha/app1.cnf < /dev/null >/logs/mha/app1/manager.log 2>&1 [root@oraclem1 mha4mysql-manager-0.56]#
8.4 master死机自动切换测试在mysql的master库52.129上,执行如下命令:echo c> /proc/sysrq-trigger 后果是:然后会看到master库变成了52.130,而52.131从库也被迫去连接新的主库52.130了。
Manager自动完成了切换操作。
8.5 master手动切换先停止manager:masterha_stop --conf=/etc/masterha/app1.cnf 在备选slave和master上添加crontab –e任务,
手动切换master,命令如下 masterha_master_switch--conf=/etc/masterha/app1.cnf --master_state=dead--dead_master_host=192.168.52.129 masterha_master_switch--conf=/etc/masterha/app1.cnf --master_state=alive--new_master_host=192.168.52.130
先设置原来的master为dead,如下所示: [root@oraclem1 ~]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=dead --dead_master_host=192.168.52.129 --dead_master_ip= --dead_master_port= Fri Apr 10 04:19:36 2015 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Apr 10 04:19:36 2015 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Fri Apr 10 04:19:36 2015 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Fri Apr 10 04:19:36 2015 - [info] MHA::MasterFailover version 0.56. Fri Apr 10 04:19:36 2015 - [info] Starting master failover. Fri Apr 10 04:19:36 2015 - [info] Fri Apr 10 04:19:36 2015 - [info] * Phase 1: Configuration Check Phase.. Fri Apr 10 04:19:36 2015 - [info] Fri Apr 10 04:19:36 2015 - [info] Multi-master configuration is detected. Current primary(writable) master is 192.168.52.129(192.168.52.129:3306) Fri Apr 10 04:19:36 2015 - [info] Master configurations are as below: Master 192.168.52.130(192.168.52.130:3306), replicating from 192.168.52.129(192.168.52.129:3306), read-only Master 192.168.52.129(192.168.52.129:3306), replicating from 192.168.52.130(192.168.52.130:3306) Fri Apr 10 04:19:36 2015 - [info] GTID failover mode = 0 Fri Apr 10 04:19:36 2015 - [info] Dead Servers: Fri Apr 10 04:19:36 2015 - [error][/usr/local/share/perl5/MHA/MasterFailover.pm, ln187] None of server is dead. Stop failover. Fri Apr 10 04:19:36 2015 - [error][/usr/local/share/perl5/MHA/ManagerUtil.pm, ln177] Got ERROR: at /usr/local/bin/masterha_master_switch line 53 [root@oraclem1 ~]#
然后设置新的master为alive,在切换过程中,界面几次自动输入YES,最后会有Switchingmaster to 192.168.52.130(192.168.52.130:3306) completed successfully.提示标志着手动切换成功,如下所示: [root@oraclem1 ~]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=192.168.52.130 Fri Apr 10 04:28:06 2015 - [info] MHA::MasterRotate version 0.56. Fri Apr 10 04:28:06 2015 - [info] Starting online master switch.. Fri Apr 10 04:28:06 2015 - [info] Fri Apr 10 04:28:06 2015 - [info] * Phase 1: Configuration Check Phase.. Fri Apr 10 04:28:06 2015 - [info] Fri Apr 10 04:28:06 2015 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Apr 10 04:28:06 2015 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Fri Apr 10 04:28:06 2015 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Fri Apr 10 04:28:06 2015 - [info] Multi-master configuration is detected. Current primary(writable) master is 192.168.52.129(192.168.52.129:3306) Fri Apr 10 04:28:06 2015 - [info] Master configurations are as below: Master 192.168.52.130(192.168.52.130:3306), replicating from 192.168.52.129(192.168.52.129:3306), read-only Master 192.168.52.129(192.168.52.129:3306), replicating from 192.168.52.130(192.168.52.130:3306) Fri Apr 10 04:28:06 2015 - [info] GTID failover mode = 0 Fri Apr 10 04:28:06 2015 - [info] Current Alive Master: 192.168.52.129(192.168.52.129:3306) Fri Apr 10 04:28:06 2015 - [info] Alive Slaves: Fri Apr 10 04:28:06 2015 - [info] 192.168.52.130(192.168.52.130:3306) Version=5.6.12-log (oldest major version between slaves) log-bin:enabled Fri Apr 10 04:28:06 2015 - [info] Replicating from 192.168.52.129(192.168.52.129:3306) Fri Apr 10 04:28:06 2015 - [info] 192.168.52.131(192.168.52.131:3306) Version=5.6.12-log (oldest major version between slaves) log-bin:enabled Fri Apr 10 04:28:06 2015 - [info] Replicating from 192.168.52.129(192.168.52.129:3306) It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 192.168.52.129(192.168.52.129:3306)? (YES/no): YES Fri Apr 10 04:28:09 2015 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time.. Fri Apr 10 04:28:09 2015 - [info] ok. Fri Apr 10 04:28:09 2015 - [info] Checking MHA is not monitoring or doing failover.. Fri Apr 10 04:28:09 2015 - [info] Checking replication health on 192.168.52.130.. Fri Apr 10 04:28:09 2015 - [info] ok. Fri Apr 10 04:28:09 2015 - [info] Checking replication health on 192.168.52.131.. Fri Apr 10 04:28:09 2015 - [info] ok. Fri Apr 10 04:28:09 2015 - [info] 192.168.52.130 can be new master. Fri Apr 10 04:28:09 2015 - [info] From: 192.168.52.129(192.168.52.129:3306) (current master) +--192.168.52.130(192.168.52.130:3306) +--192.168.52.131(192.168.52.131:3306) To: 192.168.52.130(192.168.52.130:3306) (new master) +--192.168.52.131(192.168.52.131:3306) Starting master switch from 192.168.52.129(192.168.52.129:3306) to 192.168.52.130(192.168.52.130:3306)? (yes/NO): yes Fri Apr 10 04:28:13 2015 - [info] Checking whether 192.168.52.130(192.168.52.130:3306) is ok for the new master.. Fri Apr 10 04:28:13 2015 - [info] ok. Fri Apr 10 04:28:13 2015 - [info] ** Phase 1: Configuration Check Phase completed. Fri Apr 10 04:28:13 2015 - [info] Fri Apr 10 04:28:13 2015 - [info] * Phase 2: Rejecting updates Phase.. Fri Apr 10 04:28:13 2015 - [info] master_ip_online_change_script is not defined. If you do not disable writes on the current master manually, applications keep writing on the current master. Is it ok to proceed? (yes/NO): yes Fri Apr 10 04:28:18 2015 - [info] Locking all tables on the orig master to reject updates from everybody (including root): Fri Apr 10 04:28:18 2015 - [info] Executing FLUSH TABLES WITH READ LOCK.. Fri Apr 10 04:28:18 2015 - [info] ok. Fri Apr 10 04:28:18 2015 - [info] Orig master binlog:pos is mysql-bin.000185:120. Fri Apr 10 04:28:18 2015 - [info] Waiting to execute all relay logs on 192.168.52.130(192.168.52.130:3306).. Fri Apr 10 04:28:18 2015 - [info] master_pos_wait(mysql-bin.000185:120) completed on 192.168.52.130(192.168.52.130:3306). Executed 0 events. Fri Apr 10 04:28:18 2015 - [info] done. Fri Apr 10 04:28:18 2015 - [info] Getting new master's binlog name and position.. Fri Apr 10 04:28:18 2015 - [info] mysql-bin.000058:578 Fri Apr 10 04:28:18 2015 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.52.130', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000058', MASTER_LOG_POS=578, MASTER_USER='repl', MASTER_PASSWORD='xxx'; Fri Apr 10 04:28:18 2015 - [info] Setting read_only=0 on 192.168.52.130(192.168.52.130:3306).. Fri Apr 10 04:28:18 2015 - [info] ok. Fri Apr 10 04:28:18 2015 - [info] Fri Apr 10 04:28:18 2015 - [info] * Switching slaves in parallel.. Fri Apr 10 04:28:18 2015 - [info] Fri Apr 10 04:28:18 2015 - [info] -- Slave switch on host 192.168.52.131(192.168.52.131:3306) started, pid: 14563 Fri Apr 10 04:28:18 2015 - [info] Fri Apr 10 04:28:18 2015 - [info] Log messages from 192.168.52.131 ... Fri Apr 10 04:28:18 2015 - [info] Fri Apr 10 04:28:18 2015 - [info] Waiting to execute all relay logs on 192.168.52.131(192.168.52.131:3306).. Fri Apr 10 04:28:18 2015 - [info] master_pos_wait(mysql-bin.000185:120) completed on 192.168.52.131(192.168.52.131:3306). Executed 0 events. Fri Apr 10 04:28:18 2015 - [info] done. Fri Apr 10 04:28:18 2015 - [info] Resetting slave 192.168.52.131(192.168.52.131:3306) and starting replication from the new master 192.168.52.130(192.168.52.130:3306).. Fri Apr 10 04:28:18 2015 - [info] Executed CHANGE MASTER. Fri Apr 10 04:28:18 2015 - [info] Slave started. Fri Apr 10 04:28:18 2015 - [info] End of log messages from 192.168.52.131 ... Fri Apr 10 04:28:18 2015 - [info] Fri Apr 10 04:28:18 2015 - [info] -- Slave switch on host 192.168.52.131(192.168.52.131:3306) succeeded. Fri Apr 10 04:28:18 2015 - [info] Unlocking all tables on the orig master: Fri Apr 10 04:28:18 2015 - [info] Executing UNLOCK TABLES.. Fri Apr 10 04:28:18 2015 - [info] ok. Fri Apr 10 04:28:18 2015 - [info] All new slave servers switched successfully. Fri Apr 10 04:28:18 2015 - [info] Fri Apr 10 04:28:18 2015 - [info] * Phase 5: New master cleanup phase.. Fri Apr 10 04:28:18 2015 - [info] Fri Apr 10 04:28:18 2015 - [info] 192.168.52.130: Resetting slave info succeeded. Fri Apr 10 04:28:18 2015 - [info] Switching master to 192.168.52.130(192.168.52.130:3306) completed successfully. [root@oraclem1 ~]#
PS:手动切换后,使用masterha_check_repl不能使用原来的/etc/masterha/app1.cnf来做check,要用新的app2.cnf来做check,因为app1.cnf里面的master是原来旧的cnf,check会报错主从复制失败。如何生成新的app2.cnf,很简单,如下所示: (1)复制原理的app1.cnf为新的app2.cnf cp /etc/masterha/app1.cnf/etc/masterha/app2.cnf (2)编辑app2.cnf,将里面的server1和server2的ip互换,也就是switch的两个主从的ip换掉,如下所示: [server1] hostname=192.168.52.130 candidate_master=1 master_binlog_dir=/home/data/mysql/binlog/
[server2] hostname=192.168.52.129 #candidate_master=1 #master_binlog_dir=/home/data/mysql/binlog/ (3)然后在使用masterha_check_repl --conf=/etc/masterha/app2.cnf进行check,就可以看到switch后的mha的主从是ok的了。
9报错记录总结报错记录1:[root@data01 ~]# masterha_check_repl--conf=/etc/masterha/app1.cnf Tue Apr 7 22:31:06 2015 - [warning] Global configuration file/etc/masterha_default.cnf not found. Skipping. Tue Apr 7 22:31:07 2015 - [info] Reading application default configuration from/etc/masterha/app1.cnf.. Tue Apr 7 22:31:07 2015 - [info] Reading server configuration from/etc/masterha/app1.cnf.. Tue Apr 7 22:31:07 2015 - [info] MHA::MasterMonitor version 0.56. Tue Apr 7 22:31:07 2015 - [error][/usr/local/share/perl5/MHA/Server.pm,ln303] Getting relay log directory orcurrent relay logfile from replication table failed on192.168.52.130(192.168.52.130:3306)! Tue Apr 7 22:31:07 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln424] Error happened on checking configurations. at /usr/local/share/perl5/MHA/ServerManager.pmline 315 Tue Apr 7 22:31:07 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln523] Error happened on monitoring servers. Tue Apr 7 22:31:07 2015 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK! [root@data01 ~]#
解决办法:在192.168.52.130上面,vim /etc/my.cnf,在里面添加 relay-log=/home/data/mysql/binlog/mysql-relay-bin 然后重启mysql,再去重新设置slave连接。 STOP SLAVE; RESET SLAVE; CHANGE MASTER TOMASTER_HOST='192.168.52.129',MASTER_USER='repl',MASTER_PASSWORD='repl_1234',MASTER_LOG_FILE='mysql-bin.000178',MASTER_LOG_POS=459; START SLAVE; Ok,搞定了。
报错记录2:
[root@data01 perl]# masterha_check_repl--conf=/etc/masterha/app1.cnf Thu Apr 9 00:54:32 2015 - [warning] Global configuration file/etc/masterha_default.cnf not found. Skipping. Thu Apr 9 00:54:32 2015 - [info] Reading application default configuration from/etc/masterha/app1.cnf.. Thu Apr 9 00:54:32 2015 - [info] Reading server configuration from/etc/masterha/app1.cnf.. Thu Apr 9 00:54:32 2015 - [info] MHA::MasterMonitor version 0.56. Thu Apr 9 00:54:32 2015 - [error][/usr/local/share/perl5/MHA/Server.pm,ln306] Getting relay log directory orcurrent relay logfile from replication table failed on 192.168.52.130(192.168.52.130:3306)! Thu Apr 9 00:54:32 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln424] Error happened on checking configurations. at/usr/local/share/perl5/MHA/ServerManager.pm line 315 Thu Apr 9 00:54:32 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln523] Error happened on monitoring servers. Thu Apr 9 00:54:32 2015 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK! [root@data01 perl]#
解决方法: /etc/masterha/app1.cnf文件里面的参数配置,user和repl_user都是mysql账号,需要创建好,这里是只创建了repl_user而没有创建好user账号: user=manager password=manager_1234 repl_user=repl repl_password=repl_1234
在mysql节点上,建立允许manager 访问数据库的“ manager manager ”账户,主要用于SHOW SLAVESTATUS,RESET SLAVE; 所以需要执行如下命令: GRANT SUPER,RELOAD,REPLICATIONCLIENT,SELECT ON *.* TO manager@'192.168.52.%' IDENTIFIED BY 'manager_1234';
错误记录3:
[root@oraclem1 ~]# masterha_check_repl--conf=/etc/masterha/app1.cnf Thu Apr 9 23:09:05 2015 - [warning] Global configuration file/etc/masterha_default.cnf not found. Skipping. Thu Apr 9 23:09:05 2015 - [info] Reading application default configuration from/etc/masterha/app1.cnf.. Thu Apr 9 23:09:05 2015 - [info] Reading server configuration from/etc/masterha/app1.cnf.. Thu Apr 9 23:09:05 2015 - [info] MHA::MasterMonitor version 0.56. Thu Apr 9 23:09:05 2015 - [error][/usr/local/share/perl5/MHA/ServerManager.pm,ln781] Multi-master configuration is detected, but two or more masters areeither writable (read-only is not set) or dead! Check configurations fordetails. Master configurations are as below: Master 192.168.52.130(192.168.52.130:3306),replicating from 192.168.52.129(192.168.52.129:3306) Master 192.168.52.129(192.168.52.129:3306),replicating from 192.168.52.130(192.168.52.130:3306)
Thu Apr 9 23:09:05 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln424] Error happened on checking configurations. at/usr/local/share/perl5/MHA/MasterMonitor.pm line 326 Thu Apr 9 23:09:05 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln523] Error happened on monitoring servers. Thu Apr 9 23:09:05 2015 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK! [root@oraclem1 ~]#
解决办法: mysql> set global read_only=1; Query OK, 0 rows affected (0.00 sec)
mysql>
报错记录4:
Thu Apr 9 23:54:32 2015 - [info] Checking SSH publickey authentication andchecking recovery script configurations on all alive slave servers.. Thu Apr 9 23:54:32 2015 - [info] Executing command : apply_diff_relay_logs --command=test--slave_user='manager' --slave_host=192.168.52.130 --slave_ip=192.168.52.130--slave_port=3306 --workdir=/var/tmp --target_version=5.6.12-log--manager_version=0.56 --relay_dir=/home/data/mysql/data--current_relay_log=mysqld-relay-bin.000011 --slave_pass=xxx Thu Apr 9 23:54:32 2015 - [info] Connecting to root@192.168.52.130(192.168.52.130:22).. Can't exec "mysqlbinlog": No suchfile or directory at /usr/local/share/perl5/MHA/BinlogManager.pm line 106. mysqlbinlog version command failed with rc1:0, please verify PATH, LD_LIBRARY_PATH, and client options at/usr/local/bin/apply_diff_relay_logs line 493 Thu Apr 9 23:54:32 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln205] Slaves settings check failed! Thu Apr 9 23:54:32 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln413] Slave configuration failed. Thu Apr 9 23:54:32 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln424] Error happened on checking configurations. at /usr/local/bin/masterha_check_repl line 48 Thu Apr 9 23:54:32 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln523] Error happened on monitoring servers. Thu Apr 9 23:54:32 2015 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK! [root@oraclem1 ~]#
解决办法: [root@data02 ~]# type mysqlbinlog mysqlbinlog is/usr/local/mysql/bin/mysqlbinlog [root@data02 ~]# [root@data02 ~]# ln -s/usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
报错记录5:Thu Apr 9 23:57:24 2015 - [info] Connecting to root@192.168.52.130(192.168.52.130:22).. Checking slave recovery environment settings.. Relay log found at /home/data/mysql/data, up to mysqld-relay-bin.000013 Temporary relay log file is /home/data/mysql/data/mysqld-relay-bin.000013 Testing mysql connection and privileges..sh: mysql: command not found mysql command failed with rc 127:0! at/usr/local/bin/apply_diff_relay_logs line 375 main::check()called at /usr/local/bin/apply_diff_relay_logs line 497 eval{...} called at /usr/local/bin/apply_diff_relay_logs line 475 main::main()called at /usr/local/bin/apply_diff_relay_logs line 120 Thu Apr 9 23:57:24 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln205] Slaves settings check failed! Thu Apr 9 23:57:24 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln413] Slave configuration failed. Thu Apr 9 23:57:24 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln424] Error happened on checking configurations. at /usr/local/bin/masterha_check_repl line 48 Thu Apr 9 23:57:24 2015 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm,ln523] Error happened on monitoring servers. Thu Apr 9 23:57:24 2015 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!
解决办法: ln -s /usr/local/mysql/bin/mysql/usr/bin/mysql 报错记录6:Fri Apr 10 00:58:36 2015 - [info] Executing command : apply_diff_relay_logs--command=test --slave_user='manager' --slave_host=192.168.52.130--slave_ip=192.168.52.130 --slave_port=3306 --workdir=/var/tmp--target_version=5.6.12-log --manager_version=0.56--relay_dir=/home/data/mysql/data--current_relay_log=mysqld-relay-bin.000011 --slave_pass=xxx Fri Apr 10 00:58:36 2015 - [info] Connecting to root@192.168.52.130(192.168.52.130:22).. Checking slave recovery environment settings.. Relay log found at /home/data/mysql/data, up to mysqld-relay-bin.000013 Temporary relay log file is/home/data/mysql/data/mysqld-relay-bin.000013 Testing mysql connection and privileges..Warning: Using a password onthe command line interface can be insecure. ERROR 1142 (42000) at line 1: CREATEcommand denied to user 'manager'@'192.168.52.130' for table'apply_diff_relay_logs_test' mysql command failed with rc 1:0! at/usr/local/bin/apply_diff_relay_logs line 375 main::check()called at /usr/local/bin/apply_diff_relay_logs line 497 eval{...} called at /usr/local/bin/apply_diff_relay_logs line 475 main::main()called at /usr/local/bin/apply_diff_relay_logs line 120 Fri Apr 10 00:58:37 2015 -[error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln205] Slaves settingscheck failed! Fri Apr 10 00:58:37 2015 -[error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln413] Slave configurationfailed. Fri Apr 10 00:58:37 2015 -[error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln424] Error happened onchecking configurations. at/usr/local/bin/masterha_check_repl line 48 Fri Apr 10 00:58:37 2015 -[error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln523] Error happened onmonitoring servers. Fri Apr 10 00:58:37 2015 - [info] Got exitcode 1 (Not master dead).
MySQL Replication Health is NOT OK! 解决办法: 执行如下授权语句sql: GRANT CREATE,INSERT,UPDATE,DELETE,DROP ON*.* TO manager@'192.168.52.%'; |
自学PHP网专注网站建设学习,PHP程序学习,平面设计学习,以及操作系统学习
京ICP备14009008号-1@版权所有www.zixuephp.com
网站声明:本站所有视频,教程都由网友上传,站长收集和分享给大家学习使用,如由牵扯版权问题请联系站长邮箱904561283@qq.com